**** Looking BACK to 2012 ****

A long standing adage about corporate data sources is: "80% of Business Data is Unstructured". This quote has been referenced so many times, it is hard to find the original attribution. Some say IBM quoted this number first in conjunction with the initial release of DB2 in 1983. Others say Merill-Lynch in 1998. IDC, Gartner and Forrester quote this number so often, it suspect it is etched on their office walls.
Do a Google search for "big data unstructured" and you will find that text data is the key to solving all your big data woes.
I certainly agree that managing unstructured data is essential. But is that all there is?

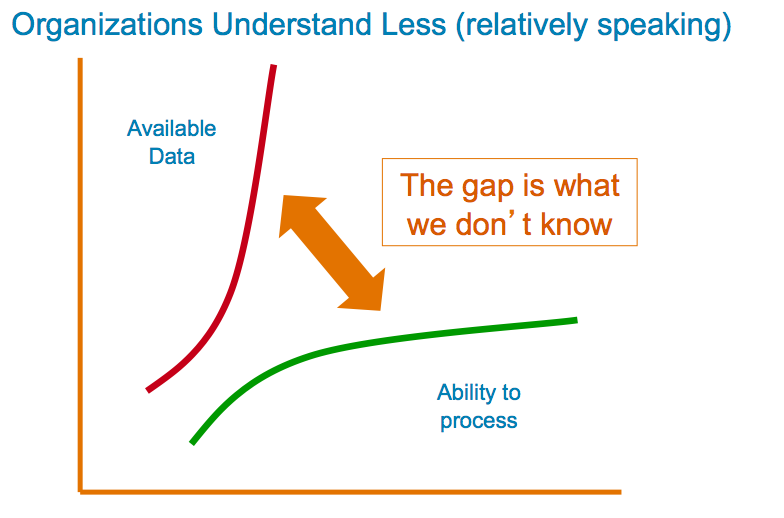
Big data is about correlating vast amounts of information. Up to 95% of business data is locked in data silos making it inaccessible to other business segments. Security is a concern but incompatible data keys remain the most common barrier.
Governments report to constituents as frequently as an SEC company. Infrastructure details, population statistics, transportation data and demographics are examples of the valuable information provided by various levels of the private sector. After asking over 100 partners and customers, I found only one who uses government data regularly. In this small sample, over 99% of users didn't leverage government data. Most admitted they had never even thought of it.
Next Time: Leveraging structured data